Machine Learning Techniques
Empowered by extensive experience and state-of-the-art equipment, Creative Biolabs has been a world-leading custom manufacturer in the area of hit identification. Now, we are proud to introduce our high-quality machine learning-based virtual screening service for early-phase drug discovery and development.
What are Machine Learning-based Methods?
Machine learning-based methods have been widely used in various fields, such as drug discovery, structural biology, and cheminformatics. Based on high-dimensional data processing capability, they are suitable for virtual screening of large compound libraries to classify molecules as active or inactive or to rank based on their activity levels. Generally, machine-learning methods mainly focus on two parts, classification and activity prediction of molecules. As to classification, it means a machine-learning method takes as input a training set of objects that have previously been classified into two or more classes. In the virtual screening context, this would be a set of molecules that had previously been tested and shown to be either active or inactive. Then, these training-set molecules are analyzed to develop a decision rule that can be used to classify new molecules into one of the two classes.
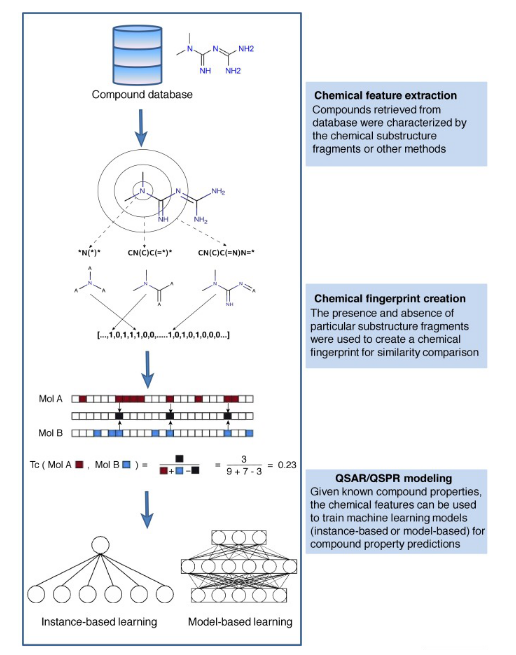 Fig.1 Computational workflow for chemoinformatics analysis using machine learning. (Lo, 2018)
Fig.1 Computational workflow for chemoinformatics analysis using machine learning. (Lo, 2018)
The first application of machine learning in drug discovery was substructural analysis (SSA), which was described by Cramer et al. as a tool for the automated analysis of biological screening data. Currently, popular machine-learning approaches in ligand-based virtual screening include, for example, artificial neural networks, kernel methods, such as support vector machines, decision trees or forests, and statistical approaches, such as Bayesian modeling. The goal of all these methods is to predict compound class labels (e.g., active versus inactive) on the basis of models derived from training sets, as well as to provide a ranking of database compounds according to the probability of activity.
Machine Learning Methods Available at Creative Biolabs
In the past, many different statistical, probabilistic, and optimization techniques have been implemented as the learning methods such as logistic regression, artificial neural networks (ANN), K-nearest neighbor (KNN), decision trees (DT), and Naive Bayes. Creative Biolabs has developed and validated numerous machine learning-based methods for virtual screening. Particularly, we offer support vector machine (SVM) technique as well as binary kernel discrimination methods to solve the most challenging computer-based drug discovery problems. All computations are run on Creative Biolabs’ infrastructures and the results of the simulations generated during the execution of service belong to the client.
Features of Our Services
- Fast prediction potential drug candidates with a short turnaround time
- Experienced scientists and professional data interpretation
- Multiple methods for option
- Best after-sale service
Creative Biolabs is dedicated to freeing up your time for core work and projects. Our service can be designed to meet your special needs if you have any requirements. If you are interested in our service, please directly contact us and our team will get back to you as soon as possible.
Reference
- Lo, Y.C., et al. Machine learning in chemoinformatics and drug discovery. Drug discovery today. 2018. 23(8): 1538-1546.
For Research Use Only.